少し大きめの XML ファイルのフォーマット変換が必要になり、かつその中に含まれている URI から画像をダウンロードしなければならない。その URI は Scene7 の画像 URL であり、重複行もあるのでそれをフィルターして効率よく処理したい。
ということで、Talend Data Integrator 使ってやってみた。Context Variables を利用すれば良いことはわかったものの、その使い方サンプルで良いものが見つけられず、手探りでなんとか達成。
この処理部分の最終形としてはこんな感じ。
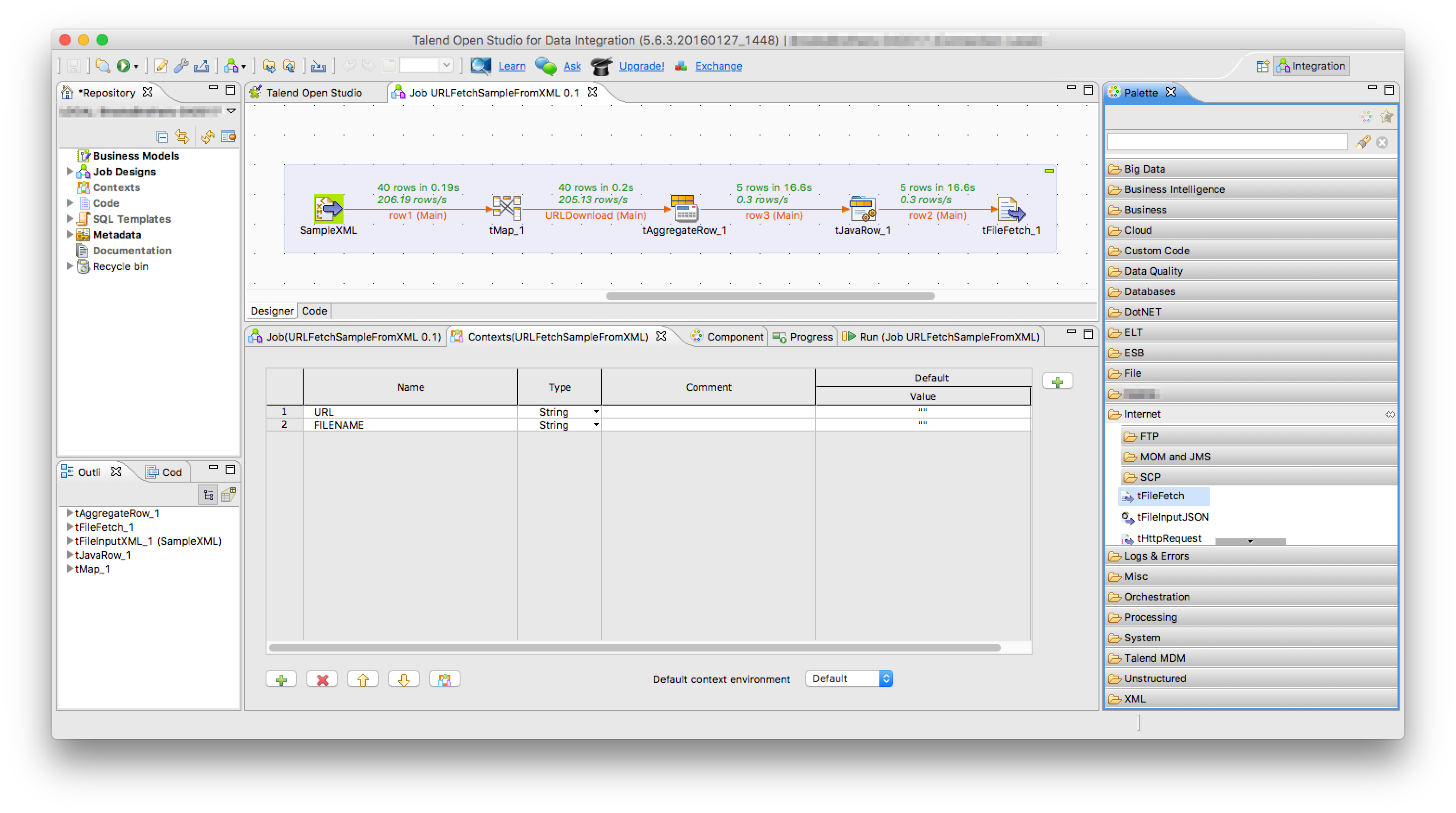
ポイントは Context として必要なパラメータを設定しておくこと。初期値は以前は “” として空白値を入れておく必要があったが、おそらく何も設定しない null でも問題ないと思う。
フロー
- tFileInputXML
- XMLファイルを読み込み、XMLノードごとの値をフィールドとして取得
- tMap
- XML から取得したフィールドを加工して URI と保存するための FILENAME に出力
- tAggregateRow
- 重複行をまとめるための処理 (同じ URI 値にてグループ化)
- tJavaRow
- tAggregateRow で GroupBy した後のフィールド値を Context に格納
- tFileFetch
- Context を変数として URI と保存ファイル名に使用
いくつかポイントとなるフローの部分を以下に説明。
tMap
今回は URL と filename の二つがあればOKなので、サンプルのXMLからこの二つを設定。保存するためのファイル名はXMLになかったため、単純にURLから該当する部分を取得
- image_link: XML から取得
- filename: image_link の末尾に該当する部分があったためそれを取得 StringHandling.EREPLACE(row1.image_link,”.*\\/”,””)
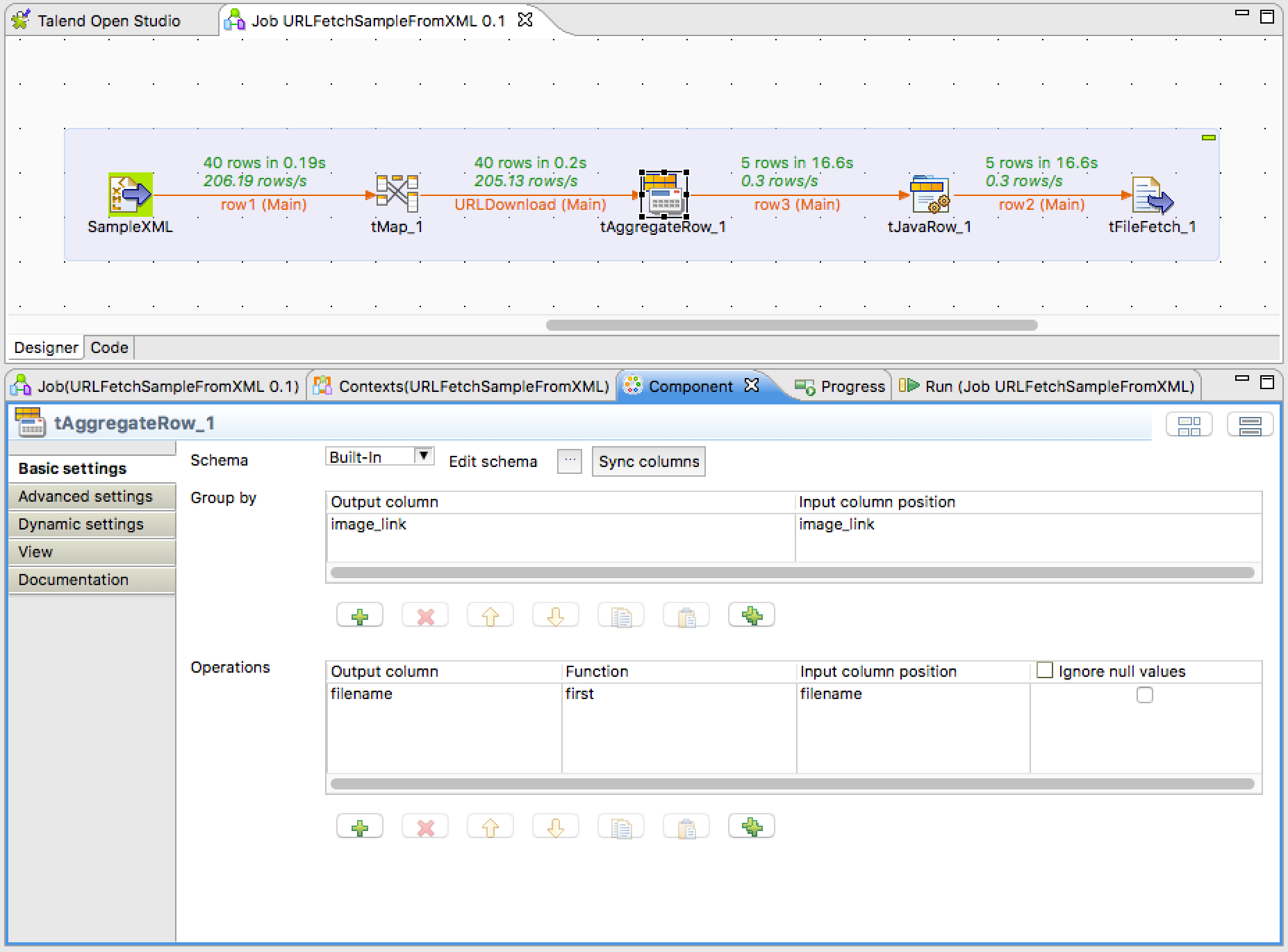
tAggregateRow
Group by のキーに URI (image_link) を指定し、他の列データである filename も出力したいため Operations に指定。Operations の Function は初期値が count になっているので最初にマッチした値の first を設定。
tJavaRow
この処理にて input_row.image_link と input_row.filename を context.URL と context.FILENAME に格納
context.URL = input_row.image_link;
context.FILENAME = input_row.filename;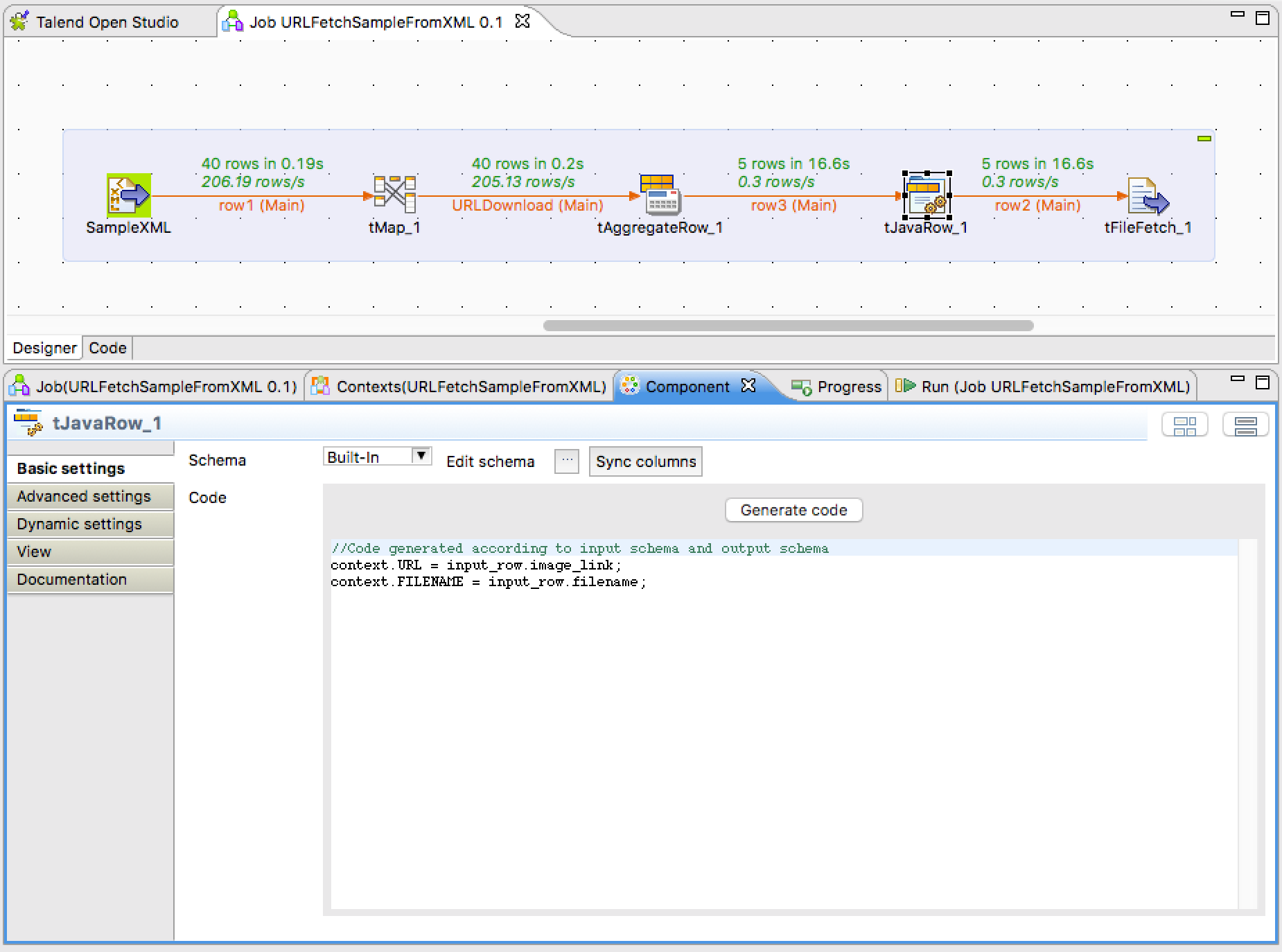
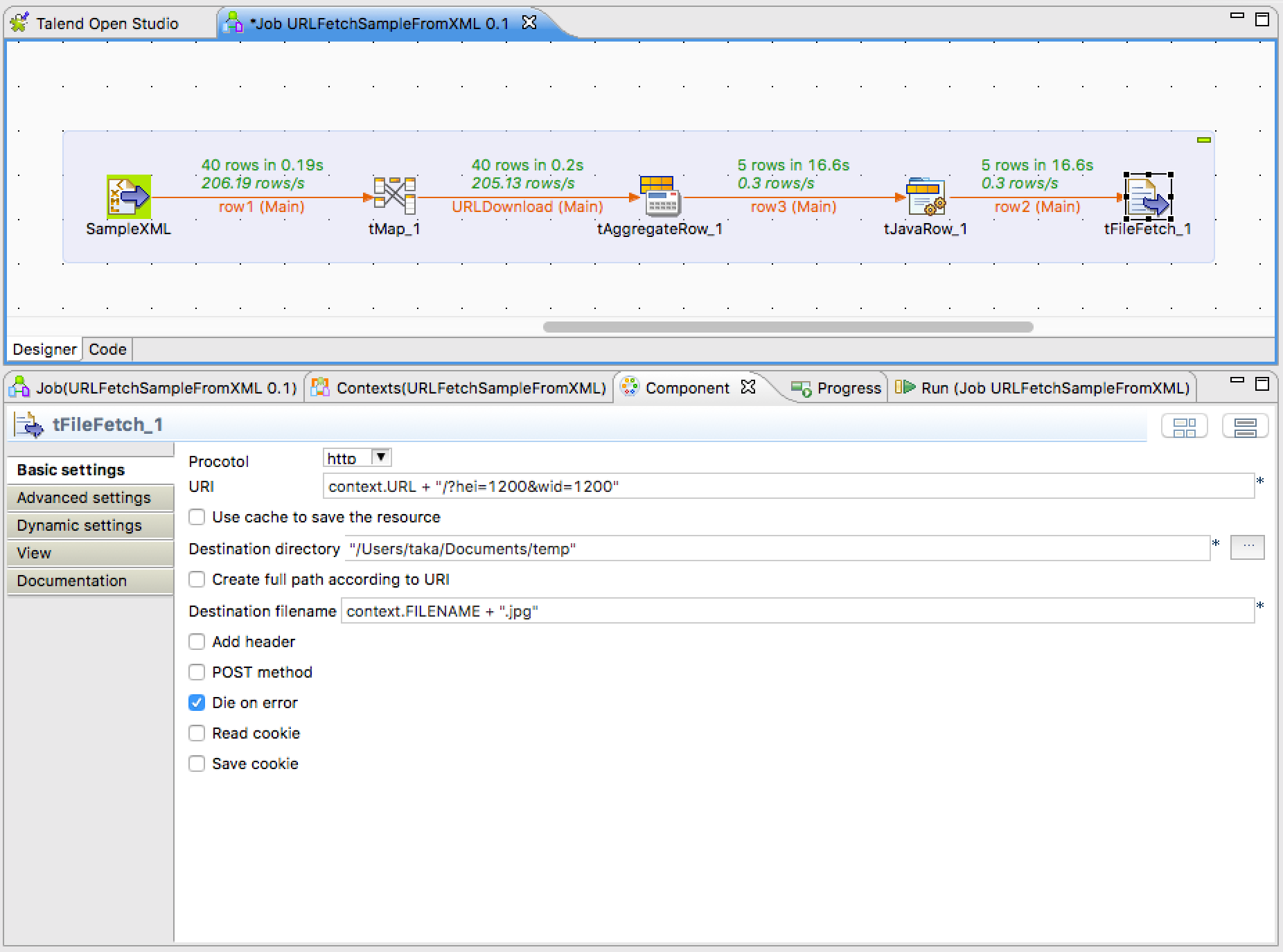
tFileFetch
この処理にて Scene7 からイメージをダウンロード。この tFileFetch は POST か GET の指定ができるが、Scene7 は GET なので POST method のチェックを外し、URI パラメータを URI フィールドに直接指定して対応。
これにて複数の画像URLが指定されているファイルからのダウンロード自動化が完了。